You can have the cleanest datasets in the world—and still fail at AI.
This harsh reality confronts many manufacturing and industrial leaders who believe their artificial intelligence journey begins with pristine spreadsheets and perfectly structured databases—that is, "clean" data. However, AI success isn't powered by spotless data alone. It thrives on contextually rich information that accurately reflects how work gets done. Organizations only see return on investment (ROI) when their data management practices, data governance policies, and enterprise data ecosystem tools actually work together. The resulting disconnect explains why throwing money at AI rarely delivers the promised results.
These contextual challenges align with industry observations that organizations need to treat data and AI as products that evolve within their specific operational environment, versus one-size-fits-all solutions that are merely implemented. Successful companies focus on transforming both clean and contextually rich data into meaningful action.
The myth of data quality
According to our AI Readiness Briefing, organizations in the early deployment phases often lack the data systems necessary to deploy AI effectively. The problem isn't just data cleanliness—it's that clean but contextless datasets lead to shallow, brittle AI models and applications that fail to deliver meaningful business value.
Consider this scenario in manufacturing: Production line sensors are perfectly calibrated and generate flawless data streams. Yet the AI-powered quality prediction model keeps failing because there's no documentation capturing how experienced operators make manual adjustments during certain weather conditions. These crucial operational insights—the metadata and semantic details—remain invisible to the AI system, despite the technical "cleanliness" of the sensor data.
Why context matters more than you think
Context refers to the essential background elements—including environmental conditions, process variations, human decisions, and cross-source dependencies—that surround raw data and transform it into meaningful information.
Contextual data captures:
Data origin: Information about data sources, collection methods, and transformations, which establishes trustworthiness and enables proper interpretation of data quality
Environmental factors: Conditions like ambient temperature, humidity, or even the time of day that impact quality or performance, but often get lost in data preparation steps
Temporal data: Historical patterns and trends that provide a perspective on how data has changed over time and reveal insights that point-in-time analysis might miss
Organization context: The business objectives, strategic priorities, and intended use cases that frame why the data was collected and how it should be applied to create value
Tacit knowledge: The undocumented tweaks and field experience that veteran employees rely on but rarely document
Process interdependencies: The connections between different systems and workflows that are critical for AI systems and machine learning algorithms
Despite growing interest and investment, many mid-market companies still struggle to translate AI into value. According to TXI’s AI Readiness Briefing, more than half of companies are still wrestling with the fundamentals of implementation—underscoring that the missing ingredient is often context, not cleanliness.
Case in point: context-rich data with Dickson
TXI's partnership with Dickson, a leading manufacturer of environmental monitoring solutions, provides a perfect example of how contextual data transforms business outcomes. Over two decades, Dickson grew from making data loggers into a technology-forward company with DicksonOne, their flagship environmental monitoring platform.
The challenge wasn't just collecting clean data from environmental sensors. The critical insight came when the team recognized that operators had valuable contextual knowledge about environmental conditions that wasn't being captured in the digital systems. Take hospital staff monitoring vaccine refrigerators, for instance. They'd notice subtle patterns in temperature fluctuations that indicated potential issues before standard thresholds were triggered.
Dickson's monitoring solutions became significantly more valuable to users by designing systems that captured this operational context. The breakthrough came with the development of DicksonOne, which integrated real-time notifications with contextual information. For vaccine refrigeration, this meant nurses received alerts that incorporated not just temperature data, but also contextual information about what actions were needed based on how long conditions had been out of range. This context-focused approach helped Dickson become an international leader in environmental monitoring.
How to build context-rich, AI-ready data
Building truly AI-ready data requires a deliberate approach that goes beyond traditional data cleaning and preparation. Here's how to advance your data readiness:
Step 1: Capture 'Dark Data'
Don't just wire up obvious metrics—interview operators, audit informal workflows, and identify the unofficial knowledge that keeps operations running smoothly. This means observing how people actually work, not just how processes are documented.
Look for places where operators:
Override automatic settings
Make adjustments based on experience
Use unofficial workarounds
Interpret primary data differently based on external factors
Then ensure these insights enrich your data repositories with contextualized inputs that give AI systems the complete picture.
Step 2: Create information, not just data
Structure formats and validation rules around how decisions are actually made, tying observability into real-world operations. This means capturing not just what happened but why certain actions were taken.
For example, don't just log that a production parameter was adjusted—document the circumstances that triggered the adjustment, the reasoning behind it, and the expected outcome. This context transforms raw data into actionable information.
Step 3: Preserve human knowledge
Build data catalogs and systems where expert insights are captured alongside primary data to support AI-powered decision-making. This might include:
Annotating datasets with operator comments
Creating knowledge repositories linked to production data
Developing standard ways to capture exceptions and special cases
Implementing collaborative tools that allow experts to add context to automated systems
According to research from McKinsey, the most AI-ready organizations are investing 20-25% of their AI budgets in knowledge management and training systems—significantly more than companies that struggle with AI implementation.
Step 4: Design for decision support, not full automation
Use AI solutions to augment, not replace, human judgment—ensuring actionable insights fit your team's operational lens. This means designing systems that:
Present AI insights in ways that match how operators think about problems
Provide context for recommendations, not just the recommendations themselves
Allow for human override and feedback that improves the system
Focus on the decisions that need to be made, not just the data that can be collected
Organizations focusing on decision augmentation rather than full automation consistently report higher satisfaction with their AI investments and better operational outcomes. When AI systems enhance human expertise rather than trying to replace it, they create more resilient operations that adapt to changing conditions.
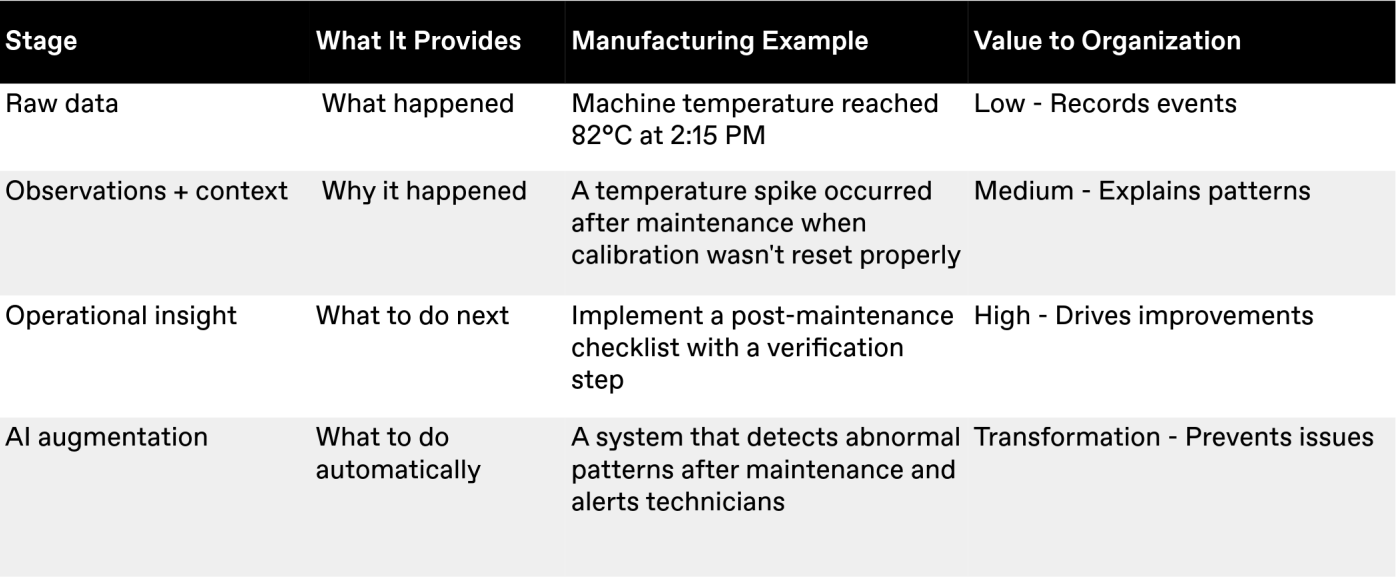
The Journey from data to action
As Katie Wolf, TXI's Head of Design, explains, "Our pragmatic approach prioritizes the client's needs over our own. Sensor readings tell you what happened. But context tells you why—and what to do next. That's the difference between noise and insight."
This natural progression captures how context transforms raw data into actionable intelligence: